Yushuf Sharker, Eben Kenah
PLOS Computational Biology
January 20, 2021
ABSTRACT
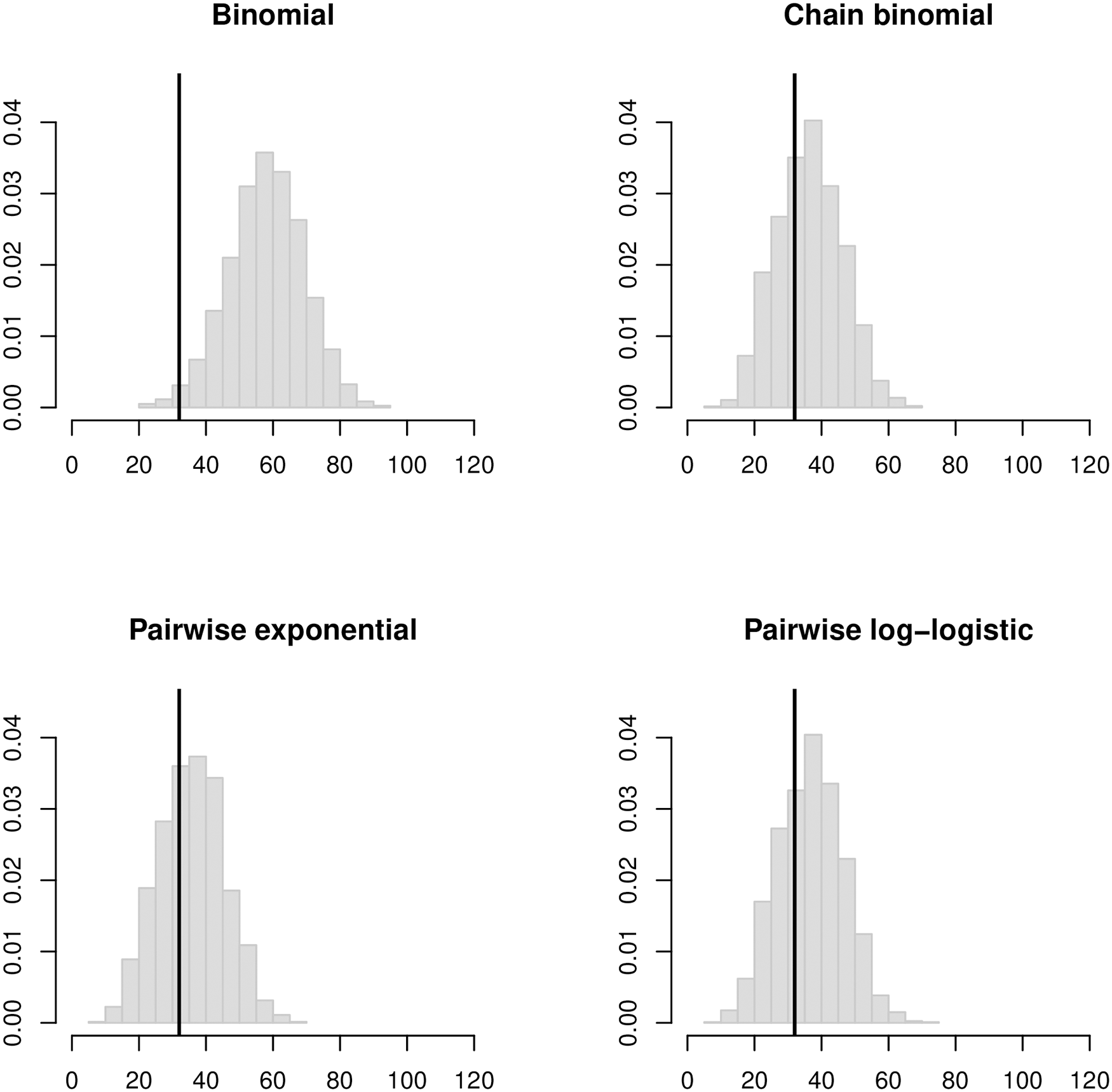
The household secondary attack risk (SAR), often called the secondary attack rate or secondary infection risk, is the probability of infectious contact from an infectious household member A to a given household member B, where we define infectious contact to be a contact sufficient to infect B if he or she is susceptible. Estimation of the SAR is an important part of understanding and controlling the transmission of infectious diseases. In practice, it is most often estimated using binomial models such as logistic regression, which implicitly attribute all secondary infections in a household to the primary case. In the simplest case, the number of secondary infections in a household with m susceptibles and a single primary case is modeled as a binomial(m, p) random variable where p is the SAR. Although it has long been understood that transmission within households is not binomial, it is thought that multiple generations of transmission can be neglected safely when p is small. We use probability generating functions and simulations to show that this is a mistake. The proportion of susceptible household members infected can be substantially larger than the SAR even when p is small. As a result, binomial estimates of the SAR are biased upward and their confidence intervals have poor coverage probabilities even if adjusted for clustering. Accurate point and interval estimates of the SAR can be obtained using longitudinal chain binomial models or pairwise survival analysis, which account for multiple generations of transmission within households, the ongoing risk of infection from outside the household, and incomplete follow-up. We illustrate the practical implications of these results in an analysis of household surveillance data collected by the Los Angeles County Department of Public Health during the 2009 influenza A (H1N1) pandemic.